Vectorize.io
Optimize RAG pipelines for LLMs by importing, experimenting, and deploying vectors
Accurate retrieval-augmented generation (RAG) platform
Experiment with different chunking and embedding
Refine vectorization strategy and improve LLM context
Pricing:
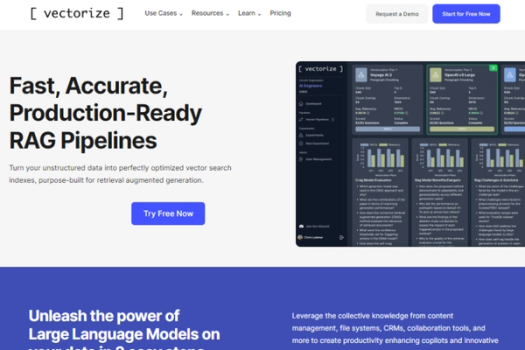


What is Vectorize.io
Vectorize.io is a platform engineered to optimize retrieval-augmented generation (RAG) pipelines for large language models (LLMs). It allows users to import data from various sources, experiment with different chunking and embedding strategies, and deploy real-time vector pipelines. This enables the creation of generative AI applications that enhance productivity and customer experiences by utilizing the collective knowledge from content management and collaboration tools.
Key Features of Vectorize.io
- Fast, Accurate RAG Pipelines: Enables the creation of production-ready Retrieval-Augmented Generation (RAG) pipelines, ensuring your data is always up-to-date and accurately indexed.
- Three-Step Deployment: Easily unleash the power of Large Language Models on your data with steps to import, experiment, and deploy.
- Import Capabilities: Upload documents or connect to external knowledge management systems to extract natural language for use by your LLM.
- Experimentation Tools: Test a multitude of chunking and embedding strategies in parallel, using recommendations or selecting your own for optimal results.
- Real-time Deployment: Convert selected vector configurations into real-time pipelines that automatically update when changes occur to maintain accurate search results.
- Wide Integration: Out-of-the-box connectors to popular knowledge repositories, collaboration platforms, CRMs, and more, making it easy to turn organizational knowledge into generative AI.
- Top AI Platforms Support: Includes support for embedding models and chunking strategies from Hugging Face, Google Vertex, LangChain, AWS Bedrock, OpenAI, Microsoft Azure, Jina AI, Voyage AI, and Mistral AI.
- Automatic Index Creation: Automatically create and update vector indexes in your preferred vector database, making your data AI-ready.
- User-Friendly Interface: Designed to make the identification of optimal embedding models and vectorization strategies straightforward, offering a free trial to get started quickly.
- RAG Sandbox and Experiments: Features a sandbox for end-to-end testing and experimenting with different vectorization strategies to refine and enhance LLM context.
Pricing
Free Plan:
- Cost: $0/month
- Features:
- 1 free simple RAG pipeline
- Update vector indexes daily
- Up to 5 experiments/month
- Up to 2 users
- Community Support via Discord
Starter Plan:
- Cost: $89/month
- Features:
- Up to 3 RAG pipelines
- Update vector indexes daily
- Up to 3 users
- Up to 15 experiments/month
- Community support via Discord
Professional Plan:
- Cost: $399/month
- Features:
- Up to 10 RAG pipelines
- Update vector indexes hourly
- Up to 10 users
- Up to 50 experiments/month
- 24x5 support with SLA
Enterprise Plan:
- Cost: Contact Us
- Features:
- More than 50 experiments/month
- More than 10 vector pipelines
- More than 10 users
- Email, chat, and video support 24x7 with 2-hour SLA
Vectorize.io
Optimize RAG pipelines for LLMs by importing, experimenting, and deploying vectors
Key Features
Links
Visit Vectorize.ioProduct Embed
Subscribe to our Newsletter
Get the latest updates directly to your inbox.
Share This Tool
Related Tools



Allow cookies
This website uses cookies to enhance the user experience and for essential analytics purposes. By continuing to use the site, you agree to our use of cookies.