Google Cloud Speech to Text
Convert speech to text with Google Cloud's advanced AI tools
Real-time and batch audio processing
Supports 125+ languages
Customizable models for domain-specific transcriptions
Pricing:
Features:

What is Google Cloud Speech to Text
Google Cloud Speech to Text is an AI-powered tool that converts audio to text using advanced speech recognition technology. It supports over 125 languages and offers real-time and batch processing capabilities for various applications, including transcribing audio files, captioning videos, and integrating speech recognition into apps. The tool leverages Google's Chirp model for improved accuracy and supports custom models and domain-specific terms, ensuring robust transcription even in noisy environments. It also provides enterprise-grade security and regulatory compliance features.
Key Features of Google Cloud Speech to Text
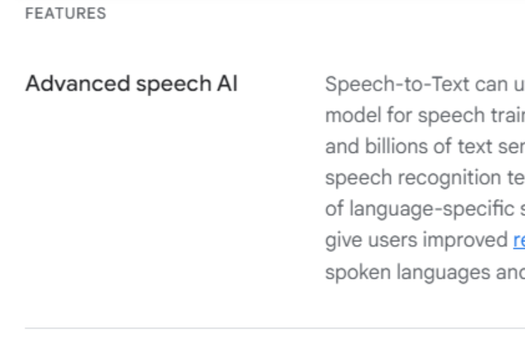
- Advanced Speech AI: Speech-to-Text leverages Chirp, Google Cloud's foundation model for speech, trained on millions of hours of audio data and billions of text sentences, offering improved recognition and transcription for more spoken languages and accents.
- Support for 125 Languages and Variants: The tool supports transcription for a global user base with over 125 languages, including specialized recognition for different accents and dialects.
- Transcription of Various Audio Types: Users can transcribe short, long, or streaming audio using the tool, providing flexibility for different transcription needs.
- Pretrained and Customizable Models: Choose from diverse pretrained models for voice control, phone call, and video transcription, or customize models to meet specific domain quality requirements through the Speech-to-Text UI.
- Regulatory and Security Compliance: Speech-to-Text API v2 includes out-of-the-box features like audit logging, data residency options in multiple regions, and enterprise-grade encryption with customer-managed encryption keys.
- Real-Time Speech Recognition: The tool provides real-time speech recognition results from audio streamed from an application's microphone or prerecorded audio files.
- Speech Adaptation: Customize the speech recognition to transcribe domain-specific terms and improve accuracy for rare or frequently used words by providing hints and boosting specific terms.
- On-Premises Solution: Offers on-premises deployment for complete control over infrastructure and protected speech data, leveraging Google’s speech recognition technology privately.
- Multichannel Recognition: Recognizes distinct channels in multichannel audio settings (e.g., video conferences) and annotates transcripts to preserve the order of speech.
- Noise Robustness: The tool can handle noisy audio from various environments without needing additional noise cancellation.
- Domain-Specific Models: Provides trained models optimized for specific domains such as telephony and video calls, ensuring high-quality transcription tailored to these contexts.
- Content Filtering: Includes a profanity filter to detect and filter out inappropriate or unprofessional content in audio data.
- Transcription Evaluation: Allows users to upload and transcribe their voice data without coding, iterating on configuration to evaluate quality.
- Automatic Punctuation: (Beta) The tool punctuates transcriptions with commas, question marks, and periods accurately.
- Speaker Diarization: Automatically predicts and annotates which speaker spoke each utterance in a conversation, useful for multi-speaker contexts.
Google Cloud Speech to Text
Convert speech to text with Google Cloud's advanced AI tools
Key Features
Product Embed
Subscribe to our Newsletter
Get the latest updates directly to your inbox.
Share This Tool
Related Tools



Allow cookies
This website uses cookies to enhance the user experience and for essential analytics purposes. By continuing to use the site, you agree to our use of cookies.